Reduce, Reuse… Refactor: Clearer Elixir with the Enum Module
“When an operation cannot be expressed by any of the functions in the Enum module, developers will most likely resort to reduce/3.” From the docs for E...

In my last post I said I would “bring in another data source, show how I linked the data together, and demonstrate the sort of bigger picture that one can get from this approach”. There’s a lot to talk about, so I’m going to break these each into different posts so that I can give them the proper attention.
In doing an analysis of a software development community, GitHub is the peanut butter to StackOverflow’s jelly. With thousands of projects on GitHub matching the search term neo4j, there’s also a big chunk of data to chew on.
The GitHub model that I imported is a bit more complex than the one for StackOveflow.
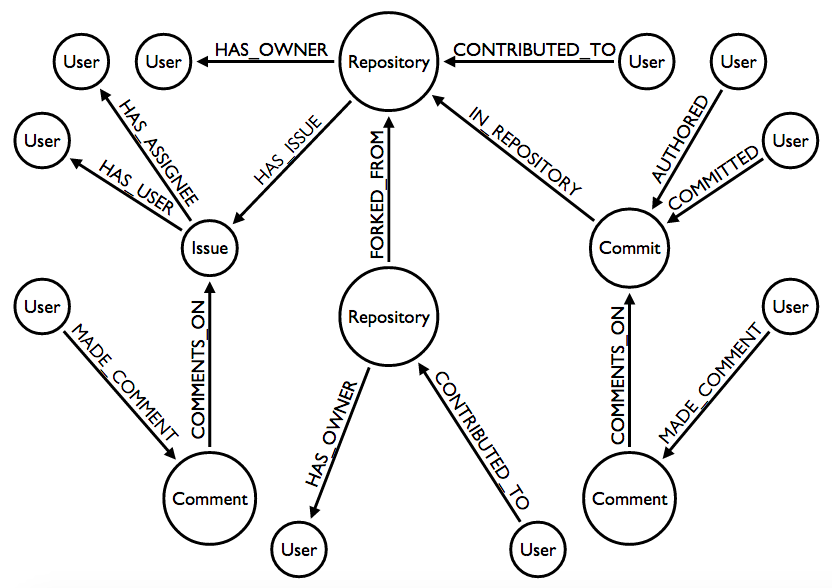
One of my goals was to examine relationships between contributors, so it made sense to import all of the places where GitHub users could interact. From the graph model you can see that this is on:
To give you a taste, I have a cypher query which UNIONs together all the different places where users can collaborate in the model:
MATCH (u1:User:GitHub)--(:Repository)--(u2:User:GitHub) WHERE u1 <> u2
RETURN u1.login, u2.login
UNION
MATCH (u1:User:GitHub)--(:Repository)-[:FORKED_FROM]-(:Repository)--(u2:User:GitHub) WHERE u1 <> u2
RETURN u1.login, u2.login
UNION
MATCH (u1:User:GitHub)-[:HAS_ASSIGNEE|:HAS_USER|:COMMENTS_ON|:MADE_COMMENT*1..2]-(:Issue)-[:HAS_ASSIGNEE|:HAS_USER|:COMMENTS_ON|:MADE_COMMENT*1..2]-(u2:User:GitHub) WHERE u1 <> u2
RETURN u1.login, u2.login
UNION
MATCH (u1:User:GitHub)-[:AUTHORED|:COMMITTED|:COMMENTS_ON|:MADE_COMMENT*1..2]-(:Commit)-[:AUTHORED|:COMMITTED|:COMMENTS_ON|:MADE_COMMENT*1..2]-(u2:User:GitHub) WHERE u1 <> u2
RETURN u1.login, u2.login
After a bit of post-processing we get the following top 20 results:
| login | count | login | count | |
|---|---|---|---|---|
| jexp | 2060 | wfreeman | 1087 | |
| peterneubauer | 1937 | rickardoberg | 1076 | |
| nawroth | 1345 | jakewins | 1064 | |
| systay | 1253 | tbaum | 1025 | |
| akollegger | 1248 | mneedham | 955 | |
| lassewesth | 1209 | jimwebber | 940 | |
| jotomo | 1188 | karabijavad | 939 | |
| dmontag | 1177 | nigelsmall | 924 | |
| maxdemarzi | 1155 | jadell | 913 | |
| simpsonjulian | 1115 | cleishm | 893 |
Some time ago as part of creating the neo4apis gem I had created a gem to import data from GitHub. With this project I had the opportunity to more fully use neo4apis-github and to flesh it out a bit more. There were two changes which I introduced:
User nodes will also now have a GitHub label instead of having only a GitHubUser label.For this project I’ve made and released (on GitHub of course) the script which I used to import the data.
The script imports repositories found from searching for neo4j on the GitHub API search endpoint. Those repositories are passed into neo4apis-github, and then for each repository it imports:
The neo4apis-github gem takes care of importing the immediately associated users for all of the above (such as the owner of a repository or the owner and assignee of an issue)
All together I was able to import:
In my next post I’ll show the process of how I linked the orignal StackOveflow data with the new GitHub data. Stay tuned for that, but in the meantime I’d also like to share the more technical details of what I did for those who are interested.
The biggest challenge in writing the script was finding a way to cache the GitHub API endpoints. In developing the script it was useful to be able to build and run just one thing (e.g. just importing the repositories) and then build more on top of that. By creating a cache of the API results I don’t need to re-request the repository endpoints when I run a new version of the script to import issues, commits, and comments. Also, when my script failed half-way, as it did many times for many reasons, I can simply run it again and generally within 30 seconds it will have picked up where it left off.
The caching mechanism that I used was the ActiveSupport::Cache::FileStore class. The activesupport gem has a number of built-in caching stores with a common API so that they can be swapped out. MemoryStore and MemCacheStore are popular, but I went with FileStore for a persisted cache without needing to set up anything else.
My first attempt to use a FileStore could be considered somewhat clever, but in the end was too frustrating. Such is the life of a programmer…
I wanted to take the results of the github_api gem and store them in the cache, but the gem uses method chaining like this:
github_client.repos.list
# or
github_client.users.followers.list
So I created a class called GithubClientCache (source code gist) which takes a GithubClient object from the github_api gem at instantiation like so:
github_client_cache = GithubClientCache.new(github_client)
github_client_cache.repos.list # fetched from the API
github_client_cache.repos.list # cached
It seemed like a simple enough solution to the problem and a good excuse to use Ruby’s method_missing. Unfortunately due to what I think is a bug in the hashie gem which github_api used to store responses, the cached request couldn’t be processed correctly and would throw an error.
After some research I found out that the faraday_middleware gem supports just the sort of caching I wanted. Also, according to the github_api gem’s README, one can add custom middleware. Unfortunately that didn’t work! After debugging for a while I decided, in the interest of getting something working quickly, to dig into the source code and engadge in some good ‘ol fashioned monkey patching. You can see the result here. It’s a wholesale copy/paste of the method in question which means it is vulnerable to breaking if the gem changes, but I was fine with the tradeoff for now.
“When an operation cannot be expressed by any of the functions in the Enum module, developers will most likely resort to reduce/3.” From the docs for E...
Elixir allows application developers to create very parallel and very complex systems. Tools like Phoenix PubSub and LiveView thrive on this property of the ...
(This post was originally created for the Erlang Solutions blog. The original can be found here)
with It, Can’t Live without It
(This post was originally created for the Erlang Solutions blog. The original can be found here)
I’ve been using Elixir for a while and I’ve implemented a number of GenServers. But while I think I mostly understand the purpose of them, I’ve not gotten t...
I love Lodash, but I’m not here to tell you to use Lodash. It’s up to you to decide if a tool is useful for you or your project. It will come down to the n...
I’ve mix phx.new ed many applications and when doing so I often start with wondering how to organize my code. I love how Phoenix pushes you to think about th...
What can a 50 year old cryptic error message teach us about the software we write today?
For just over a year I’ve been obsessed on-and-off with a project ever since I stayed in the town of Skibbereen, Ireland. Taking data from the 1901 and 1911...
Recently the continuous builds for the neo4j Ruby gem failed for JRuby because the memory limit had been reached. I wanted to see if I could use my favorite...
A while ago my colleague Michael suggested to me that I draw out some examples of how my record linkage algorithm did it’s thing. In order to do that, I’ve ...
Last night I ran a very successful workshop at the Friends of Neo4j Stockholm meetup group. The format was based on a workshop that I attended in San Franci...
In my last two posts I covered the process of importing data from StackOverflow and GitHub for the purpose of creating a combined MDM database. Now we get t...
In my last post I said I would “bring in another data source, show how I linked the data together, and demonstrate the sort of bigger picture that one can ge...
Joining multiple disparate data-sources, commonly dubbed Master Data Management (MDM), is usually not a fun exercise. I would like to show you how to use a g...
I have a bit of a problem.
When using neo4j for the first time, most people want to import data from another database to start playing around. There are a lot of options including LOA...
Having recently become interested in making it easy to pull data from Twitter with neo4apis-twitter I also decided that I wanted to be able to visualize an...
I’ve been reading a few interesting analyses of Twitter data recently such as this #gamergate analysis by Andy Baio. I thought it would be nice to have a ...
I am he as you are he as you are me and we are all together – The Beatles
When I told the people of Northern Ireland that I was an atheist, a woman in the audience stood up and said, ‘Yes, but is it the God of the Catholics or t...
“Wilkins! Yes! I’ve considered decorating these walls with some graffiti of my own, and writing it in the Universal Character.. but it is too depressing...