Reduce, Reuse… Refactor: Clearer Elixir with the Enum Module
“When an operation cannot be expressed by any of the functions in the Enum module, developers will most likely resort to reduce/3.” From the docs for E...

Recently the continuous builds for the neo4j Ruby gem failed for JRuby because the memory limit had been reached. I wanted to see if I could use my favorite tool (Neo4j) to analyize the memory usage. So I threw together a bit of Ruby code to use Ruby’s ObjectSpace.each_object functionality to dump every object in memory after the test suite of the gem finished (garbage collecting first, of course). First let’s take a look at the model:
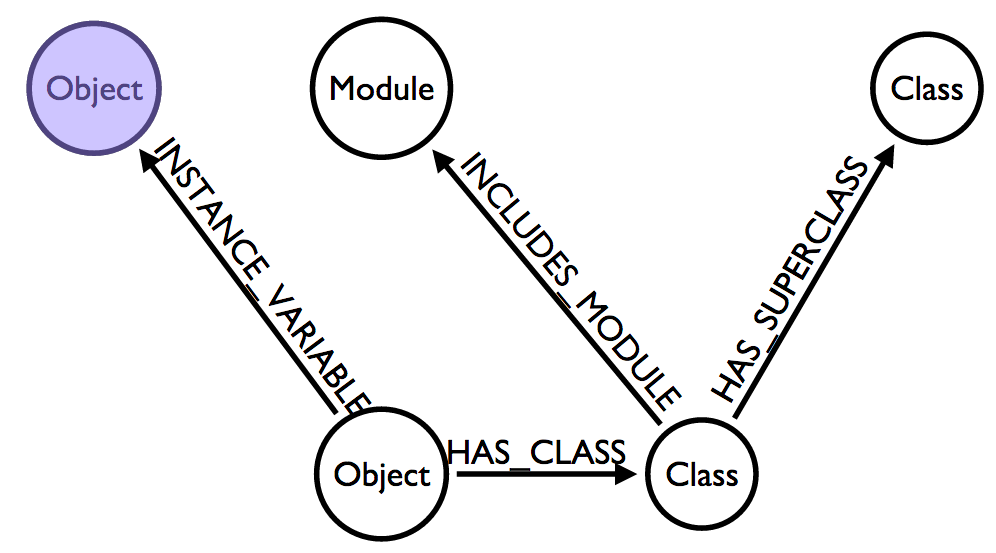
A quick Ruby primer:
Objects are always instantiations of one and only one ClassClasses can include zero or more Modules which extend their APIsObject, including Classes and ModulesSo with that in mind I set out to output some CSVs. This was my first opportunity to output some CSV files for the neo4j-import tool and it was quite a straightforward standard to implement. Here is an example of each of the files that I generated:
objects.csv
object_id:ID inspect :LABEL
70099268550680 <RubyVM::InstructionSequence:block in contains_requirable_file?@/Users/brian/.rvm/rubies/ruby-2.2.0/lib/ruby/2.2.0/rubygems/basic_specification.rb> Object
70099273105500 RubyVM::InstructionSequence Object;Class
70099273176540 Class Object;Class
70099270029100 RSpec::Core::SharedExampleGroup::TopLevelDSL Object;Module
70099273176580 Module Object;Class
70099277099900 RSpec::Core::DSL Object;Module
70099275863180 PP::ObjectMixin Object;Module
70099278769700 JSON::Ext::Generator::GeneratorMethods::Object Object;Module
70099273176460 Kernel Object;Module
instance_variables.csv
:START_ID :END_ID variable
70099268552320 70099268552120 @version
70099268552320 70099277643340 @segments
70099268552320 0 @prerelease
70099268552320 -4656870404935510835 @hash
70099268553460 70099268553260 @version
70099268553460 70099277643720 @segments
70099268553460 0 @prerelease
70099268553460 2810968934318335001 @hash
70099268558740 70099272991680 @_declared_property_manager
object_classes.csv
:START_ID :END_ID
70099273176540 70099273176540
70099273176580 70099273176540
70099277099900 70099273176580
70099275863180 70099273176580
70099278769700 70099273176580
70099273176460 70099273176580
70099270029100 70099273176580
70099273105500 70099273176540
70099268550680 70099273105500
class_superclasses.csv
:START_ID :END_ID
70271986243040 70271986243080
70272011737340 70271986239340
70271986207920 70271986243120
70271986179720 70271986243120
70271986207000 70271986243120
70271986517200 70271986243120
70271986241140 70271986243120
70271986225760 70271986225920
70271986206080 70271986243120
class_modules.csv
:START_ID :END_ID
70099273176580 70099270029100
70099273176580 70099277099900
70099273176580 70099275863180
70099273176580 70099278769700
70099273176580 70099273176460
70099273176540 70099270029100
70099273176540 70099277099900
70099273176540 70099275863180
70099273176540 70099278769700
Again, you can see the code for generating these files here.
As you can see I chose to make my files tab-separated. I did this because the inspect column was going to have lots of double quotes in it and it would create a simpler file. I also used the pipe (|) as the quoting character because of some conflicts with the way Ruby and Neo4j interpret escaping of quoted characters. Here is the command that I used to import the CSV files into a Neo4j database:
./db/bin/neo4j-import \
--delimiter TAB \
--quote "|" \
--into ./db/data/graph.db \
--nodes ./objects.csv \
--relationships:INSTANCE_VARIABLE ./instance_variables.csv \
--relationships:HAS_CLASS ./object_classes.csv \
--relationships:INCLUDES_MODULE ./class_modules.csv
Great, now we’re cooking with graphs! What does this look like in the Neo4j web console?
MATCH (o:Object) WHERE NOT(o:Class) AND NOT(o:Module) WITH o LIMIT 20
MATCH o-[:HAS_CLASS]->(c:Class)
OPTIONAL MATCH c-[:INCLUDES_MODULE]->(m:Module)
RETURN *
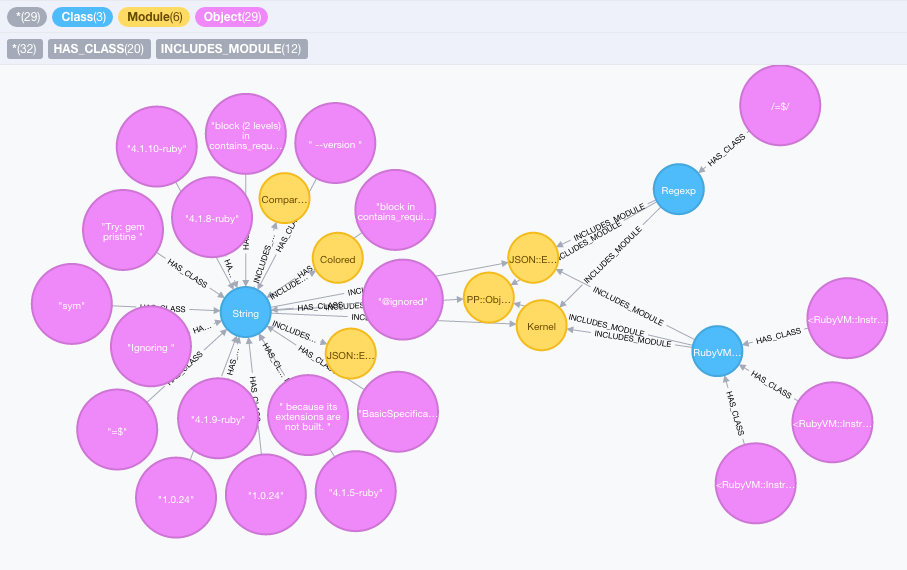
Nice! As another sanity check, let’s see what our top allocated objects are:
MATCH (o:Object)-[:HAS_CLASS]->(c:Class)
WHERE NOT(o:Class) AND NOT(o:Module)
RETURN c.inspect, count(o) ORDER BY count(o) DESC LIMIT 10
| c.inspect | count(o) | c.inspect | count(o) |
|---|---|---|---|
| String | 171,082 | RubyVM::Env | 17,731 |
| Array | 53,532 | Gem::Requirement | 4,227 |
| Proc | 21,894 | RSpec::Core::Hooks::HookCollection | 3,252 |
| RubyVM::InstructionSequence | 19,416 | Gem::Dependency | 2,973 |
| Hash | 18,081 | Regexp | 2,971 |
That seems right! Any experienced Rubyists will know that Ruby will allocate a lot of strings.
So let’s really get into it and use the power of graphs. Let’s find out which objects have the most references via instance variables. This query takes every object in the database as the root of a tree of instance variable references and calculates the total number of descendent objects in that tree. This should give us an idea for what objects have a lot of other objects depending on them which cannot be garbage collected.
// Count of tree
MATCH (o:Object) WHERE NOT(o:Class) AND NOT(o:Module) WITH o
MATCH o-[:HAS_CLASS]->(c:Class)
OPTIONAL MATCH path=o-[:INSTANCE_VARIABLE*]->(other)
RETURN c.inspect, o.inspect, count(other) ORDER BY count(other) DESC LIMIT 10
| c.inspect | o.inspect | count(other) |
|---|---|---|
| RSpec::Core::ExampleGroup::Nested_31::Nested_5 | #<RSpec::Core::ExampleGroup::Nested_31:: Nested_5:0x007f8285c325d0 @__memoized=nil, @prev_wrapped_classes=[Student(name: Object), Teacher(name: Object) … | 284 |
| Neo4j::ActiveNode::Reflection::AssociationReflection | #<Neo4j::ActiveNode::Reflection:: AssociationReflection:0x007f828a2fcfb0 @macro=:has_many, @name=:teachers, @association=#<Neo4j::ActiveNode::HasN::Ass … | 193 |
| Neo4j::ActiveNode::HasN::Association | #<Neo4j::ActiveNode::HasN:: Association:0x007f828a2fd5f0 @type=:has_many, @name=:teachers, @direction=:out, @target_class_name_from_name=”Teacher”, @ta … | 190 |
| RSpec::Core::Runner | #<RSpec::Core::Runner:0x007f82859f89e0 @options=#<RSpec::Core::ConfigurationOptions:0x007f8284241dd8 @args=[], @command_line_options={:files_or_direct … | 127 |
| Bundler::LazySpecification | #<Bundler::LazySpecification:0x007f82853c47b8 @name=”neo4j”, @version=#<Gem::Version “5.0.0.rc.2”>, @dependencies=[<Gem::Dependency type=:runtime name … | 110 |
| Bundler::LazySpecification | #<Bundler::LazySpecification:0x007f82853bdc38 @name=”neo4j-core”, @version=#<Gem::Version “5.0.0.rc.1”>, @dependencies=[<Gem::Dependency type=:runtime … | 110 |
| Bundler::LazySpecification | #<Bundler::LazySpecification:0x007f82853778c8 @name=”parser”, @version=#<Gem::Version “2.2.0.3”>, @dependencies=[<Gem::Dependency type=:runtime name=” … | 103 |
| Bundler::LazySpecification | #<Bundler::LazySpecification:0x007f8285367bd0 @name=”rainbow”, @version=#<Gem::Version “2.0.0”>, @dependencies=[], @platform=”ruby”, @source=#<Bundler … | 103 |
| Bundler::LazySpecification | #<Bundler::LazySpecification:0x007f8285395850 @name=”faraday_middleware-multi_json”, @version=#<Gem::Version “0.0.6”>, @dependencies=[<Gem::Dependency … | 103 |
| Bundler::LazySpecification | #<Bundler::LazySpecification:0x007f8285396d68 @name=”erubis”, @version=#<Gem::Version “2.7.0”>, @dependencies=[], @platform=”ruby”, @source=#<Bundler: … | 103 |
Not bad for a query which runs in 6.5 seconds (with 335,446 total objects on my MacBook Air)!
As part of the import the objects I also create a graph structure to define classes, modules, and their relationships. Let’s see what are the most included modules in our object space:
| m.inspect | count(c) | m.inspect | count(c) |
|---|---|---|---|
| Kernel | 136 | RSpec::Core::MockFrameworkAdapter | 8 |
| PP::ObjectMixin | 136 | RSpec::Core::Extensions::InstanceEvalWithArgs | 8 |
| JSON::Ext::Generator::GeneratorMethods::Object | 136 | RSpec::Core::Pending | 8 |
| Enumerable | 21 | ActiveAttr::Matchers | 8 |
| Comparable | 12 | SimpleCov::HashMergeHelper | 6 |
| RSpec::Matchers | 9 | JSON::Ext::Generator::GeneratorMethods::Hash | 6 |
| RSpec::Core::SharedExampleGroup | 8 | RSpec::Core::ExampleGroup::Nested_1::NamedSubjectPreventSuper | 3 |
| ActiveNodeRelStubHelpers | 8 | RSpec::Core::ExampleGroup::Nested_1::LetDefinitions | 3 |
| Neo4jSpecHelpers | 8 | File::Constants | 3 |
| RSpec::Core::MemoizedHelpers | 8 | SimpleCov::ArrayMergeHelper | 3 |
Looking at this I learned a couple of things I didn’t know about Ruby:
Kernel module is included everywhere (which makes sense)While we’re here let’s grab a random sample of classes and modules (excluding some ones that I hand-picked which had too many connections to make for a useful graph visualization):
MATCH (o:Object)
WHERE (o:Class OR o:Module) AND
NOT(o.inspect IN ['Class', 'Module', 'Kernel', 'PP::ObjectMixin']) AND
NOT o.inspect =~ "JSON::Ext.*"
RETURN o LIMIT 80
Here’s the graph (click to zoom):

That’s all for now, but please let me know if you have other thoughts for how to use this approach!
Along a similar line I’ve been thinking about graphing dependency trees like in RubyGems or NPM. Other project ideas are also welcome!
“When an operation cannot be expressed by any of the functions in the Enum module, developers will most likely resort to reduce/3.” From the docs for E...
Elixir allows application developers to create very parallel and very complex systems. Tools like Phoenix PubSub and LiveView thrive on this property of the ...
(This post was originally created for the Erlang Solutions blog. The original can be found here)
with It, Can’t Live without It
(This post was originally created for the Erlang Solutions blog. The original can be found here)
I’ve been using Elixir for a while and I’ve implemented a number of GenServers. But while I think I mostly understand the purpose of them, I’ve not gotten t...
I love Lodash, but I’m not here to tell you to use Lodash. It’s up to you to decide if a tool is useful for you or your project. It will come down to the n...
I’ve mix phx.new ed many applications and when doing so I often start with wondering how to organize my code. I love how Phoenix pushes you to think about th...
What can a 50 year old cryptic error message teach us about the software we write today?
For just over a year I’ve been obsessed on-and-off with a project ever since I stayed in the town of Skibbereen, Ireland. Taking data from the 1901 and 1911...
Recently the continuous builds for the neo4j Ruby gem failed for JRuby because the memory limit had been reached. I wanted to see if I could use my favorite...
A while ago my colleague Michael suggested to me that I draw out some examples of how my record linkage algorithm did it’s thing. In order to do that, I’ve ...
Last night I ran a very successful workshop at the Friends of Neo4j Stockholm meetup group. The format was based on a workshop that I attended in San Franci...
In my last two posts I covered the process of importing data from StackOverflow and GitHub for the purpose of creating a combined MDM database. Now we get t...
In my last post I said I would “bring in another data source, show how I linked the data together, and demonstrate the sort of bigger picture that one can ge...
Joining multiple disparate data-sources, commonly dubbed Master Data Management (MDM), is usually not a fun exercise. I would like to show you how to use a g...
I have a bit of a problem.
When using neo4j for the first time, most people want to import data from another database to start playing around. There are a lot of options including LOA...
Having recently become interested in making it easy to pull data from Twitter with neo4apis-twitter I also decided that I wanted to be able to visualize an...
I’ve been reading a few interesting analyses of Twitter data recently such as this #gamergate analysis by Andy Baio. I thought it would be nice to have a ...
I am he as you are he as you are me and we are all together – The Beatles
When I told the people of Northern Ireland that I was an atheist, a woman in the audience stood up and said, ‘Yes, but is it the God of the Catholics or t...
“Wilkins! Yes! I’ve considered decorating these walls with some graffiti of my own, and writing it in the Universal Character.. but it is too depressing...